こんにちは、hachi8833です。今回は短縮版でお送りいたします。
- 各記事冒頭には
![⚓]() でパーマリンクを置いてあります: 社内やTwitterでの議論などにどうぞ
でパーマリンクを置いてあります: 社内やTwitterでの議論などにどうぞ
- 「つっつきボイス」はRailsウォッチ公開前ドラフトを(鍋のように)社内有志でつっついたときの会話の再構成です
![👄]()
- お気づきの点がありましたら@hachi8833までメンションをいただければ確認・対応いたします
![🙇]()
公式の更新情報から見繕いました。
参考: 6.1.0マイルストーン 6.1.0 Milestone(84%、残り20件)
![⚓]() strict loading violationの振る舞いを変更できるようになった
strict loading violationの振る舞いを変更できるようになった
元々strict loading violationは、関連付けでオンになっている場合は常にraiseしていた。今回の変更では、railseの代わりにログ出力するオプションをアプリケーションで選べるようになる。なお、この振る舞いはstrong parametersと似ていて、デフォルトではすべての環境でraiseする。アプリケーションは、lazy loadされたすべての関連付けを探しつつ、production環境ではログ出力することもできるようになる。
raiseしないようにするには、config.active_record.action_on_strict_loading_violationを:logに設定する。
同PRより大意
# activerecord/lib/active_record/core.rb#273
+ def self.strict_loading_violation!(owner:, association:) # :nodoc:
+ case action_on_strict_loading_violation
+ when :raise
+ message = "`#{association}` called on `#{owner}` is marked for strict_loading and cannot be lazily loaded."
+ raise ActiveRecord::StrictLoadingViolationError.new(message)
+ when :log
+ name = "strict_loading_violation.active_record"
+ ActiveSupport::Notifications.instrument(name, owner: owner, association: association)
+ end
+ end
つっつきボイス:「strict loading violation?」「これはたぶん割と最近入った、ビューの中でSQLを発行できないようにする機能のことでしょうね」「そんな機能が入ってたんですか」「たしかstrict loadingを有効にしておくと、コントローラからActive Recordオブジェクトをビューに渡した後に、たとえばビューの中でpreloadingされていないhas_many関連付け先のデータを取得しようとするとSQLを発行せずにraiseするというものだったと思います」「あ〜、そういうものなんですね」「lazy loadingをraiseして見つけやすくするときなどに使えますね」
後で調べると、以下のプルリクがそれのようです(ウォッチ20200302)。
「今までは有効にすると常にraiseされていたのが、今回のプルリクでは環境に応じてraiseせずにログ出力できるようになったんですね」「今まではできなかったのか」「従来は既存のコードで後からstrict loading violationを有効にすると常にraiseされるのが不便だったけど、これはなかなかいいですね![👍]() 」
」
「調べるときはログでlazy loadedな関連付けをチェックして、修正したらraiseするように変更する感じで作業したりできるんですね」「ちょうどSELinuxでpermissive modeを使うのと似てるかも」「私もそれを思い出しました」「audit logは出すけど動作は継続するところなどが似てますね」「permissive modeを使うとちょっとドキドキする![😆]() 」
」
参考: Security-Enhanced Linux - Wikipedia
「Railsでも最終的にはraiseするようにすべきですけど、これで検証中はraiseせずにログを出せるようになった」「当初はraiseだけで実装されてたのがちょっとアグレッシブな印象ですね」
![⚓]() 新機能: マルチプルデータベース向け
新機能: マルチプルデータベース向けconnected_to_many
#40370で高粒度コネクションスワップが実装されたので、マルチプルデータベースに接続できる新しいAPIが必要だ。その理由は、たとえば5つのデータベースのうち3つに読み取り用に接続して残りは書き込み用にしたい場合に、このAPIでネストが深くならないようにするためだ。
このAPIがあれば、以下のように書く代わりに
AnimalsRecord.connected_to(role: :reading) do
MealsRecord.connected_to(role: :reading) do
Dog.first # read from animals replica
Dinner.first # read from meals replica
Person.first # read from primary writer
end
end
以下のように書ける。
ActiveRecord::Base.connected_to_many([AnimalsRecord, MealsRecord], role: :reading) do
Dog.first # read from animals replica
Dinner.first # read from meals replica
Person.first # read from primary writer
end
これは過去の2つのデータベースのネストが深くなる場合に特に便利になるだろう。
同PRより大意
#40370は以前見たときはWIPでした(ウォッチ20201020)。
つっつきボイス:「connected_to_manyは上のサンプルコードがわかりやすい」「connected_to_manyという名前でいいんだろうかという気がしないでもないですけど」「今までは接続先が同じでもネストしないと書けなかったのが、ネストせずに書けるようになった」「このぐらいならネストしててもいいかなとも思いましたけど、機能が増えたのはいいですね![👍]() 」
」
![⚓]() Host Authorizationでもリクエストを除外する機能を追加
Host Authorizationでもリクエストを除外する機能を追加
リクエストを強制SSLから除外する必要が生じる可能性があるのと同様に、Host Authorizationチェックでもリクエストを除外する必要が生じる可能性がある。アプリケーションでこの柔軟性を増すことで、適合しない可能性のあるリクエストを除外しつつHost Authorizationを有効にできるようになる。たとえば、AWS Classic Load BalancerはHostヘッダーを提供しておらず、Hostヘッダーを送信するように設定することもできない。つまり、このLoad Balanacerのヘルスチェックを使うためにはHost Authoraizationを無効にしなければならなかった。今回の変更によって、アプリケーションはHost Authorizationで必要とされるヘルスチェックリクエストを除外できるようになる。
自分は(ActionDispatch::SSLと同様の方法で)ActionDispatch::HostAuthorizationミドルウェア引数を受け取れるように変更した。hosts設定はhosts_response_appと同様、引き続き別に存在しているが、自分はssl_optionsと同じような感じでHost Authorizationをグループ化してみた。グローバルなhosts_response_appは、Host Authorization失敗のレスポンスの一部でしか使われないのであれば非推奨化するのがよいかもしれない。既存のテストも更新してメソッドのシグネチャを変更し、この除外機能を検証するテストも追加した。
同PRより大意
つっつきボイス:「Rails 6に入ったHost Authorizationは、DNS Rebindingを悪用した攻撃への対策機能で、ドメインから来るリクエストのHostヘッダーもこの機能でチェックしてたと思います」
参考: Rails 6 adds guard against DNS rebinding attacks | Saeloun Blog
参考: DNS Rebinding ~今日の用語特別版~ | 徳丸浩の日記
「このプルリクでは、そのHost Authorizationで除外リストを指定できるようになった: サンプルコード↓にもあるように、healthcheckリクエストだけ通して欲しいことがよくあります」「Hostヘッダーがついていないリクエストでもこうやって除外リストを指定して通るようにしたいですよね↓」「これはやりたいです」
# actionpack/lib/action_dispatch/middleware/host_authorization.rb#12
config.host_authorization = { exclude: ->(request) { request.path =~ /healthcheck/ } }
参考: Application Load Balancer とは - Elastic Load Balancing
「通常はX-Forwarded-ForヘッダーとX-Forwarded-Protoヘッダーがリクエストに追加されるので大丈夫なんですが、ALBのhealthcheckリクエストのようにVPCの中(つまりプライベートIP)から来るリクエストや、VPC Lambdaなどから呼び出すインターフェイスは、HTTPで直接アクセスします: このような設計は割とよくあるので、今回のように除外リストを指定することでそうしたリクエストもRailsで受信できるようになるのはいいですね![👍]() 」「ありがたい
」「ありがたい![🙏]() 」「これができないと不便なんですよ: 今まではhealthcheckを受信するためにALB healthcheck用のIPアドレス範囲設定が必要でした」
」「これができないと不便なんですよ: 今まではhealthcheckを受信するためにALB healthcheck用のIPアドレス範囲設定が必要でした」
参考: X-Forwarded-For - HTTP | MDN
参考: X-Forwarded-Proto - HTTP | MDN
![⚓]() 新機能: Railtieの
新機能: RailtieのserverブロックでRailsサーバー起動後にコードを実行できるようになった
serverは、consoleやtaskといった他のRailtieブロックと似ている。目的は、サーバー起動後にアプリケーション(つまりrailtie)でコードを読み込めるようにすること。
ユースケースとしては、WebpackやReactサーバーをdevelopment環境で起動したり、SidekiqやResqueなどの一部のジョブワーカーを起動するなどが考えられる。
現時点ではこれらのタスクはすべて別シェルで実行される必要があるので、Railsサーバーの次に別のプログラムを起動する必要がある場合は、gemメンテナーがgemのライブラリの実行方法をドキュメントに追加する必要がある。
この機能はたとえば以下のように書ける。
class SuperRailtie < Rails::Railtie
server do
WebpackServer.run
end
end
同commitより大意
つっつきボイス:「なるほど、サーバー起動後にRailtieでコードを実行できるようにするのか」「ジョブワーカーをここから起動したりすると書いてますね」
なおRailtieは、Railsのコアライブラリのひとつです↓(レールタイ: 線路の枕木(railroad tie)のもじり)。
参考: Rails::Railtie
「このように複数プロセスの起動や管理をつかさどるソフトウェアはいろいろあって、よく『プロセスマネージャー』と呼ばれたりします」「docker-composeとか」「Rubyのinvokerとか」「foremanもありますね」「powもあった」「自分は最近docker-composeでまとめて管理することが多いので、この手のプロセスマネージャーは使わなくなったな〜」「invokerはちょうど今使ってます、重いけど![😆]() 」
」
![docker/compose - GitHub]()
![code-mancers/invoker - GitHub]()
![ddollar/foreman - GitHub]()
![postageapp/powr - GitHub]()
「今回追加されたserverは、そういうプロセスマネージャーっぽいこともRailtieでできるようになったということですね: ただこれを見る限りでは、サーバー起動後にフックをかけるだけのようで、これだけでは落ちたプロセスを再起動するなどのプロセス管理まではできなさそうですが」「起動はするけど管理まではしないのか…」「serverブロックにコードを書けるので、もっと複雑なこともやろうと思えば一応できますね」
「この機能は、サンプルコードのWebpackServer.runみたいに、サーバー起動後にこれとこれだけ実行しておきたいというようなシンプルな用途に便利そう: そのためにforemanなどのプロセスマネージャーをわざわざインストールしなくても済むので」「たしかに」
![⚓]() Rails
Rails
![⚓]() Railsモデルのパターンとアンチパターン
Railsモデルのパターンとアンチパターン
- (Fatと呼ばず)重量オーバーモデル
- SQLパスタパルメザンチーズ風味
- Repositoryパターン
- マイグレーションの心得
downメソッドを必ず用意する- マイグレーションでActive Recordの呼び出しを避ける
- データのマイグレーションとスキーマのマイグレーションは分ける
つっつきボイス:「AppSignalの記事です」「なぜかfat modelのfatに取り消し線を付けてoverweightとしてますね」「fatという言葉が使い古されてきたとかそういう意図なのかな?![🤔]() 」
」
「SQL Pasta Parmesanも、もしかするとSQLがスパゲッティ状になることをわざとそう呼んでいるのかしら?」「パルメザンチーズ風味![🧀]() 」
」
参考: スパゲティプログラム - Wikipedia
# 同記事より
class SongReportService
def gather_songs_from_artist(artist_id)
songs = Song.where(status: :published)
.where(artist_id: artist_id)
.order(:title)
...
end
end
class SongController < ApplicationController
def index
@songs = Song.where(status: :published)
.order(:release_date)
...
end
end
class SongRefreshJob < ApplicationJob
def perform
songs = Song.where(status: :published)
...
end
end
「↑上のようにwhere(status: :published)のような同じ条件をあちこちにバラまくよりは、下のようにスコープにまとめる方がいいですよね↓」「これはそうですね」
# 同記事より
class Song < ApplicationRecord
...
scope :published, -> { where(published: true) }
scope :by_artist, ->(artist_id) { where(artist_id: artist_id) }
scope :sorted_by_title, { order(:title) }
scope :sorted_by_release_date, { order(:release_date) }
...
end
class SongReportService
def gather_songs_from_artist(artist_id)
songs = Song.published.by_artist(artist_id).sorted_by_title
...
end
end
class SongController < ApplicationController
def index
@songs = Song.published.sorted_by_release_date
...
end
end
class SongRefreshJob < ApplicationJob
def perform
songs = Song.published
...
end
end
「この記事では、どうしても必要な場合を除いてRepositoryパターンはおすすめしないと書かれてますね」「どうしても使いたいならたとえば以下のようにSongRepositoryにまとめる方がマシだけど、それもおすすめはできないとも書かれてる」
参考: ドメイン駆動設計 - Wikipedia
# 同記事より
class SongRepository
class << self
def find(id)
Song.find(id)
rescue ActiveRecord::RecordNotFound => e
raise RecordNotFoundError, e
end
def destroy(id)
find(id).destroy
end
def recently_published_by_artist(artist_id)
Song.where(published: true)
.where(artist_id: artist_id)
.order(:release_date)
end
end
end
class SongReportService
def gather_songs_from_artist(artist_id)
songs = SongRepository.recently_published_by_artist(artist_id)
...
end
end
class SongController < ApplicationController
def destroy
...
SongRepository.destroy(params[:id])
...
end
end
「言い換えると、Active Recordを普通に呼び出せば済むことを、わざわざRepositoryパターンでラップするなということなんでしょうね: DDD(ドメイン駆動開発)の文脈ではデータベースロジックをビジネスロジックから分離するためにRepositoryパターンのクラスを間にはさむことがありますけど、たしかに上でやっていることはActive Recordを呼び出せばできるので、ここではRepositoryパターンにしなくてもよさそう」
「なるほど、Active Recordと機能がかぶるSongRepositoryクラスをわざわざ作るのは、Active Recordをむしろ損なっているのではないかという考えかもしれませんね」「Active Recordでできない機能をRepositoryパターンで作る分には構わないと自分は思います」
なお、RepositoryパターンはHanamiで全面的に採用されています↓。
Hanamiフレームワークに寄せる私の想い(翻訳)
「ところでDDD本やデザパタ本を読むと、つい本のとおりにやってみたくなることって一度や二度はあるじゃないですか」「ああ、それ思い当たります![😅]() 」「Strategyが1個しかないのにStrategyパターンにしてしまったりとか」「Factoryが一種類しかないのにFactoryを作っちゃったりとか」「そういうノリでRepositoryを無意味に作らないようにしようということなのかもしれませんね」
」「Strategyが1個しかないのにStrategyパターンにしてしまったりとか」「Factoryが一種類しかないのにFactoryを作っちゃったりとか」「そういうノリでRepositoryを無意味に作らないようにしようということなのかもしれませんね」
「記事の後半はマイグレーションの心得についての話です」「マイグレーションにdownメソッドを書きましょうという話はそのとおりですね」
「その次は、マイグレーションの中で既存のActive Record継承モデルを直接参照するのは避けよう、という話」「ああ、これはやってはいけないとよく言われる」「Railsを長くやっている人ならやってはいけないことは知っていると思いますけど、Railsを最近始めた人だとやってしまうかもしれませんね」
「その次の、データのマイグレーションとスキーマのマイグレーションは分けようという話もそのとおり」「時間のかかるデータマイグレーションは切り離して、スキーママイグレーションでデータベースがロックされる時間が長くならないようにするべきですね」
「それほど目新しい内容ではないと思いますが、Railsで定番のアンチパターンや注意事項を押さえられるのがいいと思います![👍]() 」「Rails経験の浅い人によさそうな記事ですね」
」「Rails経験の浅い人によさそうな記事ですね」
![⚓]() listen gemが3.3.0でRuby 3やTruffleRubyに対応(Ruby Weeklyより)
listen gemが3.3.0でRuby 3やTruffleRubyに対応(Ruby Weeklyより)
つっつきボイス:「guard/listenはファイルの変更を検出するツール」「そういえば素のRailsにもlisten gemが入りますね↓」
# Rails 6で生成したGemfileより
group :development do
gem 'web-console', '4.0.1'
gem 'listen', '3.1.5'
gem 'spring', '2.1.0'
gem 'spring-watcher-listen', '2.0.1'
end
「変更通知のインターフェイスはLinuxやWindowsやmacOSでそれぞれ違っているので↓、この種のファイル変更検出では複数のOSの抽象化をサポートすることが大事」「個別のOSのファイル変更通知を直接扱ったら面倒になりますよね」
![⚓]() Q:「WindowsでRailsを開発しますか?」
Q:「WindowsでRailsを開発しますか?」
ここ3年ほど、Railsアプリ開発はmacOSでしかやっていないのですが、(リモートサービスの利用を考慮しなければ)あらゆる開発者はmacOSかLinuxのどちらかで開発しているように感じます。
そこで気になるのが、Windows上でのRailsアプリ開発がどれだけやりやすいかが気になっています。言語やシェル機能やデータベース管理などはWindows用ツールで十分提供されているのでしょうか?それともWSL 2やDockerでやる方がいいのでしょうか?
同discussionの質問より大意
つっつきボイス:「WSL 2を知らなかったとレスを付けていた開発者がいたのが気になって拾いました」「Sam SaffronさんはWSL 2はいいぞ、素のWindowsはつらいよとも書いてますね(レス)」「WSL 2はWindows上の選択肢としていいと思います、少なくともWindows版RubyバイナリでRailsを動かして開発するよりはずっといい」「同意です」
参考: WSL 2 と WSL 1 の比較 | Microsoft Docs
![⚓]() 個人のローカル環境構築は成果物にならない
個人のローカル環境構築は成果物にならない
「ちなみに自分がDockerをすすめる理由のひとつは、自分のローカル開発環境の構築ってどんなに一生懸命やっても成果物にならないからなんですよ」「そう、それですよね」「環境構築は楽しいんですけど趣味に近くなりがちなのと、環境構築に費やす時間はアウトプットが出ない時間でもあるので、DockerやVMなどを用いてより短い時間で環境構築を終える方が生産的だと思います」「そうですね」「もちろん、Windowsでの各種環境設定作業を自分でやることを厭わない人は、自分の好きな方法でやってもよいと思います」
![⚓]() Ruby
Ruby
![⚓]() スーパークラスのprivateメソッドをオーバーライドする
スーパークラスのprivateメソッドをオーバーライドする
つっつきボイス:「親クラスにあるprivateなroleメソッドは、子クラスではprivateとして見えるけどpublicとしては見えない↓、これは普通」
# 同記事より
class Parent
private
def role
'parent'
end
end
class Child < Parent
def get_role
role
end
end
Child.new.get_role # => "parent"
Child.new.private_methods.include?(:role) # => true
Child.new.public_methods.include?(:role) # => false
「でも子クラスに同名のメソッドがpublicで存在していると、元クラスのprivateなroleメソッドは見えなくなって、子クラスのpublicなroleメソッドが見えるようになる」「へぇ〜」「結果として、親クラスのprivateなroleメソッドが子クラスのpublicなroleメソッドで上書きされて、get_roleの動作が変わるのか」
class Child < Parent
def role
'child'
end
end
Child.new.get_role # => "child"
Child.new.private_methods.include?(:role) # => false
Child.new.public_methods.include?(:role) # => true
「こういう書き方を実際に使うことってあるだろうか?」「親クラスのprivateメソッドを子クラスのpublicメソッドで上書きするのってちょっとトリッキーですよね![😅]() 」「こういうことができるとは…」
」「こういうことができるとは…」
![⚓]() オブジェクト指向をどの言語で学ぶか
オブジェクト指向をどの言語で学ぶか
「ところで、Rubyのprivateメソッドは、JavaやC++などの他の言語のprivateメソッドと考え方が違っているところがありますよね」「自分はJavaから始めたのでJavaのprivateメソッドの印象が強いかも」
参考: JavaやC#の常識が通用しないRubyのprivateメソッド - give IT a try
「最近だと、オブジェクト指向言語(特にクラスを継承するタイプの言語)の仕様をどんな言語で学んでいるんでしょうね?」「あ〜、どうだろう…?」「この辺の概念って、最初にどの言語でオブジェクト指向を学ぶかで納得の仕方が違ってきそうな気がするんですよ」
「たとえばC++だと明示的にオーバーライドしないと別々の関数になるけど、Javaだと同じ名前で書けばデフォルトでオーバーライドされるといった違いがありますね」「C++はやったことなかったけどそういう仕様なんですか」「そういった書き味の部分は、外見上は似ていても内部実装が違っていたりします」
「あとRubyのprotectedがJavaやC++と考え方が違っているのも有名ですね」「protectedってどこで使ったらいいのかよくわからないかも」「使ったことありませんでした」「protectedを理解して使いこなすのは難しい…」「Gemやライブラリ開発をしないのであれば、privateとpublicで十分かもしれないという気がしています」
参考: Rubyのクラスメソッドは同じクラスのprotectedメソッドやprivateメソッドにアクセスできない - give IT a try
![⚓]() quine-relay: 128言語の生成チェインでウロボロスの蛇を形成(Ruby Weeklyより)
quine-relay: 128言語の生成チェインでウロボロスの蛇を形成(Ruby Weeklyより)
![mame/quine-relay - GitHub]()
つっつきボイス:「@mameさん作の何だか壮大なクワインプログラムです」「クワインというと真っ先に@mameさんを連想するぐらい、@mameさんが強い分野ですね」
![]()
同リポジトリより
「こ、これは何ですか?![😆]() 」「Rubyプログラムを生成するRustプログラムを生成するScalaプログラムを生成する…を128言語繰り返して、最終的にRubyに戻るそうです」「トランスパイルに次ぐトランスパイルで元に戻る、まさにウロボロスの蛇
」「Rubyプログラムを生成するRustプログラムを生成するScalaプログラムを生成する…を128言語繰り返して、最終的にRubyに戻るそうです」「トランスパイルに次ぐトランスパイルで元に戻る、まさにウロボロスの蛇![🐍]() 」「自分の尻尾は美味い
」「自分の尻尾は美味い![😋]() 」
」
参考: ウロボロス - Wikipedia
「OCamlにBASIC、いろいろある」「zshやtcshまで!」「FORTRANやFORTHもある!」「知らない言語がゴロゴロ…」「言語が多すぎてulimit -s unlimitedしないと動かないっぽい」「最終的に生成されたRubyと元のRubyのdiffを取ると完全一致するんですって」「そこまでやりますか![😆]() 」「この完全に元に戻るという動作がクワインの一種ということなんでしょうね」
」「この完全に元に戻るという動作がクワインの一種ということなんでしょうね」
参考: 【 ulimit 】コマンド――ユーザーが使用できるリソースを制限する:Linux基本コマンドTips(326) - @IT
「この分だとquine-relayのソースコード自体もクワインだったりするかも?」「ソース見てみたら、ウロボロスの蛇があしらわれている…↓」「何だかクラクラしてきた![😅]() 」
」
「クワインというものがあるって初めて知りました」「自分もRubyKaigiのアトラクション的なセッションでしか見たことがありませんでした」
参考: クワイン (プログラミング) - Wikipedia
「クワインって随分昔からあるみたいですね」「しかも聞くところによると、Webサーバーか何かで実用的なクワインの例というものがあるらしいですよ」「マジで?!」「あったあった↓、この記事ではクワインを遊びではなく機能として使っているそうです」「へぇ〜!」「これ以外で実用的なクワインの例は見たことがないですね」
参考: 自作Cコンパイラで Ken Thompson のログインハックを再現してみた - 0x19f (Shinya Kato) の日報
Thompson hack ではコンパイラ自身のプログラムが現れたら自分自身と全く同じコードを埋め込むという条件付きのクワインを使うことでソースコードから痕跡を消しつつ、セルフホストしても login を書き換える性質を引き継がせる仕組みになっています。
0x19f.hatenablog.comより
「ググって見つけた『あなたの知らない超絶技巧プログラミングの世界』という本がクワインだらけでした↓」「あ、これも@mameさんの本だ!」「クワインのスライド↓も@mameさんだ…」「なるほど、そういう方なんですね」
![]()
![]()
「なお@mameさんはIOCCC(国際難読化Cコードコンテスト)で何度も勝っています↓」「おぉ〜!」「IOCCCって今も開催されてるのか」
参考: The International Obfuscated C Code Contest
参考: IOCCC - Wikipedia
「@mameさんのアイデアの豊富さがスゴい」「以前RubyKaigiのコーナーで、どうやってこういうのを作ろうと思いつくんですかと質問されたときに、@mameさんがテクニックよりも面白いアイデアを思いつくかどうかが大事というような回答をされてた覚えがあります」「やはりネタが重要なんですね」
「このissueでのやりとり↓も好きです![❤]() 」「質問がWhy? Why?」「そして返信がWhy not? Why not?
」「質問がWhy? Why?」「そして返信がWhy not? Why not?![😆]() 」
」
つっつきの後で、@mameさんがRubyConf 2020のランチで書いたクワインが流れてきました↓。
quine-relayのビルドチェーンを見てて、何となく「これはジャックの建てた家」を思い出しました↓。こちらは循環していませんが。
参考: ジャックのたてた家 The house that Jack built :マザーグースの歌
![⚓]() その他Ruby
その他Ruby
つっつきボイス:「RubyConf 2020、今日(=つっつきの日)が最終日なのか」「タイムゾーンが日本と真逆だから平日の日本だと見るの大変かも」
![⚓]() CSS/HTML/フロントエンド/テスト/デザイン
CSS/HTML/フロントエンド/テスト/デザイン
![⚓]() POSTを冪等にする
POSTを冪等にするIdempotency-Keyヘッダの提案
つっつきボイス:「社内Slackに貼っていただいた記事です」「Idempotency-Keyは、はてブのコメントで『条件付きPUTを使えばできる』とありましたね↓」
「元記事にもあるように、StripeやPayPalやGoogle Standard PaymentsなどでもIdempotency-Keyと似たようなことは既に行われているんですけど、Idempotency-Keyが標準として定まればそれを使う方がいいでしょうね(もちろんすべてのアプリケーションで使う必要はありませんが)」「今はまだ標準では存在しないんですか?」「request-id的なものを慣例的に冪等性の保証に使うことはありますが、処理の冪等性を保証することを目的とする専用のヘッダーはまだ存在しませんね」「なるほど」
「ドラフトRFCを見ると、Idempotency-KeyにはUUIDを使うことが推奨されている↓」「ただこのキーはクライアント(ブラウザ)側で生成するものなので、そこに関するセキュリティがどうなのか知りたい」「他にも、Idempotency Fingerprintが付けられることでデータだけを変更したreplay attackなどを防ぐようですね」
参考: draft-idempotency-header-00 - The Idempotency HTTP Header Field
参考: UUID - Wikipedia
「リクエストを再生するときに元のリクエストがまだ処理中の場合はHTTP 409 Conflict↓を返すとある: こういう振る舞いが標準で定められていると、APIドキュメントを読んだりAPI仕様を設計するときの手間が省けて助かりますね」「それわかります!」「409 Conflictは前からPUT用にあったけど、提案ではこれをPOSTでも使えるようにするようですね」
参考: 409 Conflict - HTTP | MDN
「このドラフトRFCは比較的短いので実装もそんなに大変ではなさそう: それも含めて自分はこのIdempotency-Keyの提案はなかなかいいと思っています![👍]() 」「
」「Idempotency-Keyは必要がなければ使わなくてもよいのもいいですね」
![⚓]() その他
その他
![⚓]() Steamのインディーズゲーム
Steamのインディーズゲーム
つっつきボイス:「pastalogicはプログラミングをお題にしたゲームだそうです」「これはカードを使う対戦型のボードゲームなんですね」「あ、カードに気が付かなかった![😅]() 」「そういえばSteam↓でときどきこんな感じのインディーズゲームを見かけます」「プログラミングをお題にしたゲームというものは見たことなかったかも」「Steamだとそれ系のゲームもちょくちょくありますよ」
」「そういえばSteam↓でときどきこんな感じのインディーズゲームを見かけます」「プログラミングをお題にしたゲームというものは見たことなかったかも」「Steamだとそれ系のゲームもちょくちょくありますよ」
参考: Steam - Wikipedia
参考: おすすめインディーゲーム27選。担当ライターが推す2019-2020冬の良作【後編】 - ファミ通.com
「インディーズゲームはアイディア勝負な分、ときどき驚くほどいいゲームが登場しますね」「そういえばFactorio↓をやっているとプログラミングしているような気持ちになって、あっという間に15時間ぐらい溶かしちゃいます」「Factorioはマイクラ(Minecraft)でレッドストーン回路を組んでいるようなものですよね」「はい、Factorioはそれに特化したようなゲームだと思います」(以下『天穂のサクナヒメ』の話など延々)
参考: Factorio - Wikipedia
参考: Minecraft - Wikipedia
参考: テクニック/レッドストーン回路 - Minecraft Japan Wiki - アットウィキ
![⚓]() Baba Is You
Baba Is You
「ちなみにSteamのインディーズゲームの中でも、このBaba Is Youというパズルゲームは超名作です↓![👍]() 」「不思議な名前!」「何だか倉庫番がパワーアップしたみたいな画面ですね」「このゲームはたしか賞も取っていたと思います」
」「不思議な名前!」「何だか倉庫番がパワーアップしたみたいな画面ですね」「このゲームはたしか賞も取っていたと思います」
参考: Steam:Baba Is You
参考: 倉庫番 - Wikipedia
なおBaba Is Youはチューリング完全で、ライフゲームも実装できるそうです↓。
![]()
store.steampowered.comより
「基本はBabaというキャラクターを動かして、『Baba』『is』『you』や『Baba』『is』『win』などと並べる↑とクリアになるんですけど、たとえば『Rock』『is』『you』と並べると自分がBabaから岩に変わって岩を動かせるとか、『Lava』『is』『melt』にすると溶岩が溶け流れて通れるようになるなど、面ごとに意表を突くようなクリア条件が設定されているのがめちゃくちゃ面白い」「あ〜、勝利条件を書き換えることもゲームに含まれる感じなんですね」「はい、このゲームを最初にやるときは一切ヒントを見ないのがおすすめです」
「Baba Is You、任天堂SWITCHでも買えるのか、買っちゃおうかな(後で買いました)」「このゲームの面白さはぜひ体験してみることをおすすめします![😋]() 」(以下、ゲーム自作話など延々)
」(以下、ゲーム自作話など延々)
今回は以上です。
バックナンバー(2020年度第4四半期)
週刊Railsウォッチ(20201117後編)Rubyのパターンマッチングが3.0で本採用に、AWS Lambdaサイズを縮小する、AppleのM1チップほか
今週の主なニュースソース
ソースの表記されていない項目は独自ルート(TwitterやはてブやRSSやruby-jp SlackやRedditなど)です。
![]()
![]()












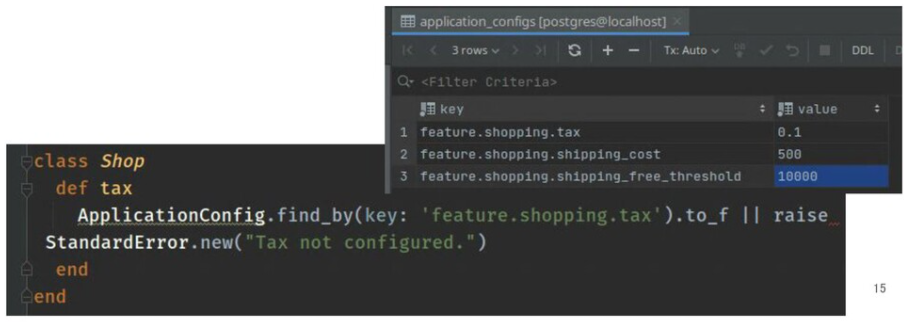
 」「コミットやプルリクのmerge順次第では、未実行のマイグレーション番号が常に最新の番号とは限らないけど、マイグレーション番号単位で具体的に未実行のものが分かるようになるのか」
」「コミットやプルリクのmerge順次第では、未実行のマイグレーション番号が常に最新の番号とは限らないけど、マイグレーション番号単位で具体的に未実行のものが分かるようになるのか」


 Railsアプリに最適なEC2インスタンスタイプとは(
Railsアプリに最適なEC2インスタンスタイプとは( 」
」
 」
」 」
」




 With it, we aim to simplify the use and setup of MeiliSearch even more
With it, we aim to simplify the use and setup of MeiliSearch even more  . With implicit index creation, you now only need to add documents to start searching.
. With implicit index creation, you now only need to add documents to start searching. 











 」「RubyのSTMはどこかで見かけたような気がする(注: 後述の笹田さん資料を参照)」「詳しい人に教わりたいです」
」「RubyのSTMはどこかで見かけたような気がする(注: 後述の笹田さん資料を参照)」「詳しい人に教わりたいです」






 」
」
 Yamada_Nt (@yamada_nt)
Yamada_Nt (@yamada_nt)  」「あのイルカ」「あのイルカだ」「あのイルカ、見かける機会が既になくなりましたよね」「若い世代だとほとんど知らないんじゃないかしら」「インターネットミームの一種か何かと思われてたりして
」「あのイルカ」「あのイルカだ」「あのイルカ、見かける機会が既になくなりましたよね」「若い世代だとほとんど知らないんじゃないかしら」「インターネットミームの一種か何かと思われてたりして
 」「あれを一度でも経験すると身に沁みます」
」「あれを一度でも経験すると身に沁みます」









 」「ワンラインパターンマッチングなどの一部のパターンマッチング機能はまだexperimentalなのか」「これで3.0になったらパターンマッチングを使ってもよくなりますね
」「ワンラインパターンマッチングなどの一部のパターンマッチング機能はまだexperimentalなのか」「これで3.0になったらパターンマッチングを使ってもよくなりますね 」「たしかにそのとおりなんですけど、これを意識的に使う機会ってあるんだろうか?」「
」「たしかにそのとおりなんですけど、これを意識的に使う機会ってあるんだろうか?」「






















 」「これができないと不便なんですよ: 今まではhealthcheckを受信するためにALB healthcheck用のIPアドレス範囲設定が必要でした」
」「これができないと不便なんですよ: 今まではhealthcheckを受信するためにALB healthcheck用のIPアドレス範囲設定が必要でした」



 」
」

 」「自分の尻尾は美味い
」「自分の尻尾は美味い






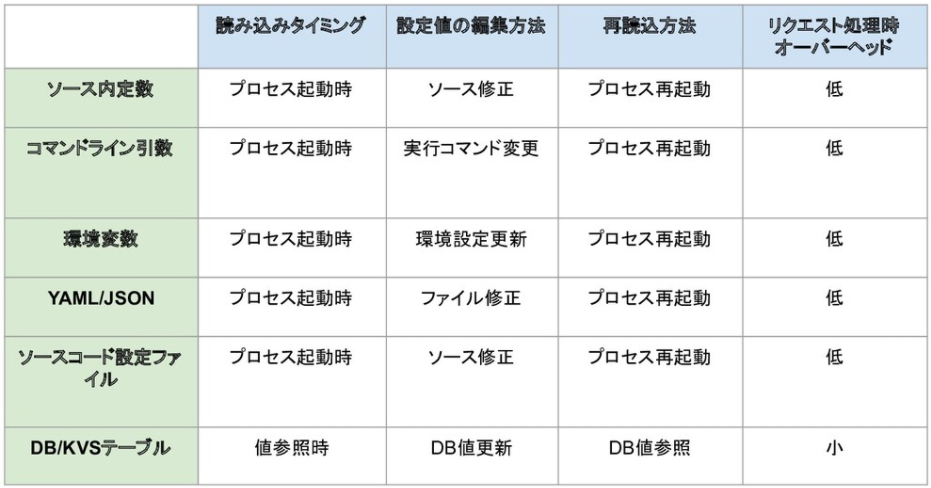
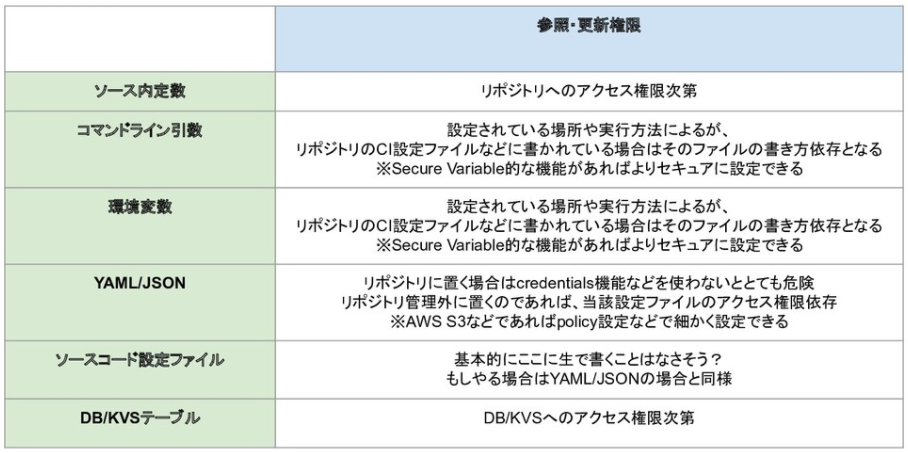
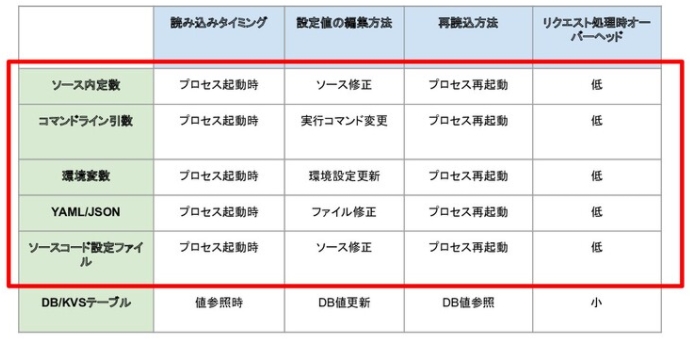







 」
」




 」「そのときにSTMの話もしてたように覚えてます」
」「そのときにSTMの話もしてたように覚えてます」







 」
」